Gut klingender Gesang ist ja bekanntlich kein Hexenwerk. Brilliant, frisch und offen sollte er klingen. Etwas Kompression, ordentlich Höhen und ein paar Effekte gehören standardmäßig drauf. Was ist aber mit dem De-Esser? Wo genau kommt er hin, und was genau soll er bezwecken?
In dieser Folge möchten wir über die allseits gefürchteten »S-Laute« beim Gesang und deren Bearbeitung sprechen. Normalerweise gibt es bei den meisten (natürlich) aufgenommenen Gesängen nicht sofort den Bedarf einer Bearbeitung durch den sogenannten De-Esser. In aller Regel klingen die Stimmen weder hart, noch gibt es übermäßige Zischlaute oder andere Störenfriede. Diese Problematik ergibt sich erst durch das Mixen. Mit starker Kompression kann die Stimme deutlich dichter und aggressiver erscheinen und der Gesang somit aufleben und richtig nach vorne kommen. Jedoch werden auch alle Störgeräusche und andere (eher leisere) Probleme, wie Atmer oder Zischlaute, verstärkt. Und wenn man dann zusätzlich noch die Höhen mit einem EQ aufdreht, um die Stimme brillant und offener klingen zu lassen, können S-Laute besonders unangenehm auffallen und zum Teil auch sehr scharf klingen. Hier greift der geübte Tontechniker zu einem De-Esser, wodurch sich die meisten S-Laute ganz einfach und i.d.R. automatisch abschwächen lassen.
Anzeige
Der klassische De-Esser ist einfach ausgedrückt ein Kompressor, der auf eine bestimmte Frequenz bzw. einen Frequenzbereich reagiert. So kann er gezielt auf die üblichen Zisch- und S-Laute eingestellt werden, um sie leiser zu machen und den Gesang zu entschärfen. Das mag in der Theorie zwar relativ einfach klingen, kann aber in der Praxis zu einem richtigen Drahtseilakt werden. Denn man sollte hier genau abschmecken. Ein zu weicher Gesang transportiert weniger Emotionen und kann den Zuhörer evtl. nicht richtig mitnehmen, während ein zu scharfer Gesang überfordern kann und abschreckend wirkt. Außerdem klingen nicht alle Zischlaute gleich, liegen in demselben Frequenzbereich oder haben die gleiche Lautstärke bzw. Betonung. So wird z. B. das Wort »singen« aggressiver ausgesprochen als »schlafen«. Ein zu schwach eingestellter De-Esser würde das erste Wort zwar abschwächen, aber das zweite gar nicht erst bearbeiten. Ein zu stark eingestellter De-Esser könnte wiederum »schlafen« gut abschwächen, aber bei dem Wort »singen« zu viel komprimieren und ein unnatürliches Lispeln erzeugen.
Zusätzlich können die Zischlaute in unterschiedlichen Frequenzbereichen liegen. So liegt der S-Laut bei dem Wort »weiß« z. B. viel höher als bei »sind«. Wäre der Frequenzbereich des De-Essers zu hoch eingestellt, würde er das zweite Wort gar nicht erst bearbeiten, während ein zu tief eingestellter Bereich zwar das zweite Wort erwischen würde, aber evtl. auch andere F-, T- und P-Laute mit bearbeiten und den Gesang so unnatürlich klingen lassen.
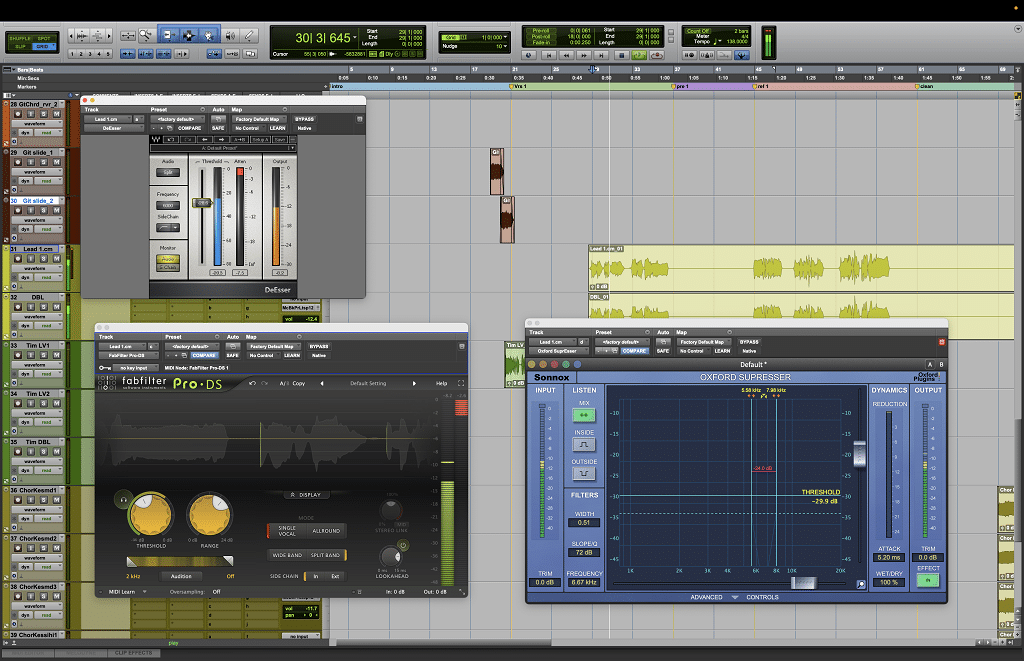
Der Waves DeEsser soll nur einige der lauteren S-Laute über 6 kHz abfangen. Der Fabfilter Pro DS schwächt alle Zischlaute ab 2 kHz ab, und der Sonnox SuprEsser greift nur bei einigen S-Lauten im Bereich von ca. 5,6 – 8 kHz ein.
Grundsätzlich gibt es hier leider keine pauschale Einstellung, die immer funktioniert, sondern man verteilt die Arbeit auf mehrere Schritte. Im ersten Schritt wird ein De-Esser vor der ersten Kompression eingesetzt. Hier ist der Gesang noch relativ dynamisch, und es werden nur einige der lauteren S-Laute abgefangen. So muss der Threshold eher hoch und der Frequenzbereich weiter oben (z. B. ab 6 kHz) liegen. Dadurch wird der Gesang nicht insgesamt weicher, sondern die S-Laute werden nur etwas aneinander angeglichen und angepasst.
Dann wird im zweiten Schritt ein De-Esser nach dem Kompressor und EQ eingesetzt. Jetzt ist die Dynamik beim Gesang kleiner, und so kann auch der Threshold tiefer eingestellt sein. Der Frequenzbereich sollte hierbei größer sein und z. B. bis 2 kHz heruntergehen. So werden deutlich mehr S-Laute abgefangen, und der Gesang sollte an Schärfe verlieren. Evtl. bleiben jetzt noch ein paar wenige S-, F- oder Sch-Laute übrig. Diese liegen oft in einem anderen Frequenzbereich und müssen gesondert behandelt werden. Im einfachsten Fall durch eine Volume-Automation, indem man sie einfach an den wenigen Stellen leiser macht. Oder man benutzt einen oder mehrere De-Esser mit einem ganz engen Frequenzbereich, der nur diese Störfrequenzen erkennt.
Alternativ dazu kann auch ein dynamischer EQ eingesetzt werden. Mit diesem lassen sich die entsprechenden Frequenzen einfach finden und dynamisch entfernen.
Auch moderne intelligente Plug-ins wie etwa Soothe2 von Oeksound würden hier helfen. Diese können Resonanzen erkennen und unterdrücken. Allerdings würde ich hier zur Vorsicht raten, da man ganz schnell auch einen leblosen Gesang bekommt kann, weil zu viele Resonanzen rausgezogen wurden.